A Guide on Running LLMs Locally
AI #LLM #LM Studio
目次 / Index
Introduction
What are LLMs?
A Large-Language Model or more commonly known as LLM, is a form of Artificial Intelligence which can recognize and generate text; common AI tools such as ChatGPT, Claude and Gemini are all considered LLMs. These models are trained through a process called Machine Learning, which helps it recognize patterns in text and by using those patterns, predict what should come next when given a user’s prompt. This way, an LLM can sound like a human by generating answers in real-time, instead of rigidly providing previous answers set in a database.
For example:
An LLM has been trained on 100 different English Essays to respond to “I need
help in writing an essay for my college assignment”. Instead of regurgitating the essays it was trained on, it will try to create an essay by its own, by using the elements and patterns which it has remembered from the training material, as well as the varying contents of the user prompts. This way, it will be able to not only write an essay but also modify it according to the user’s needs.
Of course, current advanced LLMs are trained on vast amounts of data (usually amounting to petabytes), and have billions of parameters, which helps to refine them further. Claude 3.5 Sonnet is estimated by Epoch AI , to have roughly 400 Billion parameters, and based on this rough calculation method from a user on HuggingFace, we can estimate that 1 parameter uses roughly 2-4 bytes.
Benefits of Running LLMs Locally (For Businesses and Individuals)
For businesses, their concern would definitely be to save cost. Instead of paying for API credits from an AI company like OpenAI, they can instead run their own LLM, which will have sinigficant upfront cost, but will eventually save them money in the long run.
Furthermore, there is the issue of privacy. There are concerns that vital information could be inappropriately accessed or utilized. With local LLMs, any data used for training and any responses generated will stay within that company.RetryClaude can make mistakes. Please double-check responses.
Next, there is also the ability to use LLMs without Internet Connection. For those who are running their own LLMs, on their own hardware, they do not have to access anything online, which eliminates the factors of slow Internet and frequent outages of the AI provider. Local LLMs also offer comprehensive customization through data fine-tuning to match any requirements, changing the tone in which it responds and implementation of Retrieval-Augmented Generation (RAG), which is basically giving your LLM a custom Knowledge Base.
Common Requirements
Hardware
Local LLM rigs contain the same components as a normal Desktop, such as a CPU, RAM and a Motherboard. However, they are usually much more powerful, along with a drastic increase of GPUs.

From the rig above, we can see that it is utilizing 8 GPUs, disclosed as NVIDIA RTX 3060s by the owner. Most consumer grade motherboards only have around 1-4 PCIe slots for GPUs or other expansion cards. Therefore, to achieve the rig above, a mining motherboard was utilized, specifically the BTC B75 with 8 USB PCIe slots.

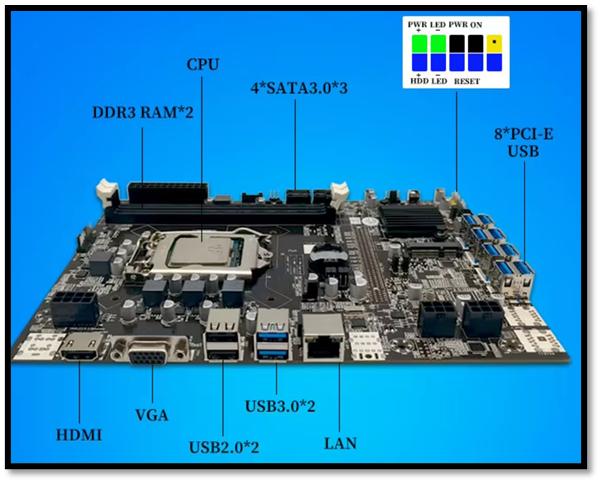
Along with the increase in GPUs, there will also be a significant increase in power usage, which is why enterprise grade PSUs are required. The rig with the 4x NVIDIA RTX3060, used a PSU with a 2400W output. For anyone who wants to build their own AI rig, you can use an online tool to count the wattage of all your components. Then, make sure to get a compatible PSU that has a good efficiency rating (Gold and above).
Software
The software requirements for each use case differ from case-to-case, since each LLM or framework may be coded in different programming languages or vary in complexity for setting up. However, these are the common software requirements used in modern day Local LLMs.
- A supported OS, such as Windows, Linux or macOS.
- Python or C++. The primary programming languages used for ML development.
- CUDA toolkit (for NVIDIA GPUs) or ROCm (for AMD GPUs). Allow LLMs to utilize GPU acceleration.
- ML framework like TensorFlow or PyTorch.
- Git. Version Control.
Common Challenges
Memory & Storage Requirements
Running LLMs locally demands substantial computing resources, with VRAM being a particular bottleneck. Most modern models need at least 8GB of VRAM just to run basic inference, with larger models easily requiring 32GB or more. One factor to note as well is that VRAM cannot be modified or added, you will have to buy a GPU card which has the pre-installed VRAM.
This challenge is compounded by the massive storage requirements. Although there are many lower-end models which do not require much storage, if you would like to get decent performance, a mid-range model such as the Llama 3.3 70B Instruct, may take up 50GB+ of disk space and you’ll often need multiple versions of the same model for testing and optimization. Furthermore, if you would like to have options and download several models, storage needs can quickly balloon into hundreds of gigabytes.
Technical Expertise
Setting up LLMs isn’t just about downloading and running software – it requires technical knowledge that falls under an AI engineer’s expertise. They need to understand everything from hardware configurations to software optimizations, particularly when it comes to advanced techniques like Quantization and Flash Attention. These optimization methods are crucial for making models run efficiently on consumer hardware, but implementing them requires careful balancing of performance, memory usage, and model accuracy. It’s not just about knowing what these techniques do but understanding when and how to apply them effectively.
Popular Methods to Run LLMs
LM Studio
LM Studio is a desktop application which basically simplifies all the processes required to run an LLM locally, such as finding and downloading model files ourselves, configuring our CPU/GPU settings, and creating an interface to interact with the model. LM Studio simplifies all this by providing a model marketplace that has all the latest models and prepares everything for the user with a single click. Once it is installed, users can immediately interact with the model through the existing interface.
LLaMa.cpp
Llama.cpp is an open-source software library that takes LLMs and compresses them through quantization to make them run more efficiently on regular computers. Users simply have to build llama.cpp on their device by following the how to guide on the GitHub page and then download any LLMs in the .gguf extension. The online model hub Hugging Face hosts many compatible models. Once the download is complete, the user can then use the model for inference through the command line or implement it within any C/C++ application.
GPT4All
GPT4All is another desktop application which allows you to run models on your laptop or computer, since users can simply download the desktop application and immediately start chatting with the default model. Furthermore, there is also a dedicated feature where you can upload any documents as material, which then allows you to ask questions about it. As it is with all other Local LLMs, GPT4All can be used offline and ensures privacy since no data leaves your device.
Quick Setup Guide (LM Studio)
For this article, we will be exploring how to set up and run an LLM locally using a straightforward method, through LM Studio. First, navigate to the LM Studio Home Page. Then, download the appropriate version for your machine. For this guide, we will be exploring the Windows version. Once the installer is downloaded, run it.
You will then be greeted with a Setup Screen. Press “Next”, double check the information it displays on screen, then proceed until you reach this screen.
Click on “Finish” to run LM Studio. You will then be greeted by the LM Studio application home page.
Click on the “Get your first LLM” button which will be DeepSeek R1 Distilled (Qwen 7B).
Click on the “Download” button, which will download the model. Keep in mind that the file size is quite large, so it might take some time.
Hooray! It is now downloaded and can be used just like any other online AI tool. Click on “Start New Chat”, then you will find an interface which is similar to ChatGPT.
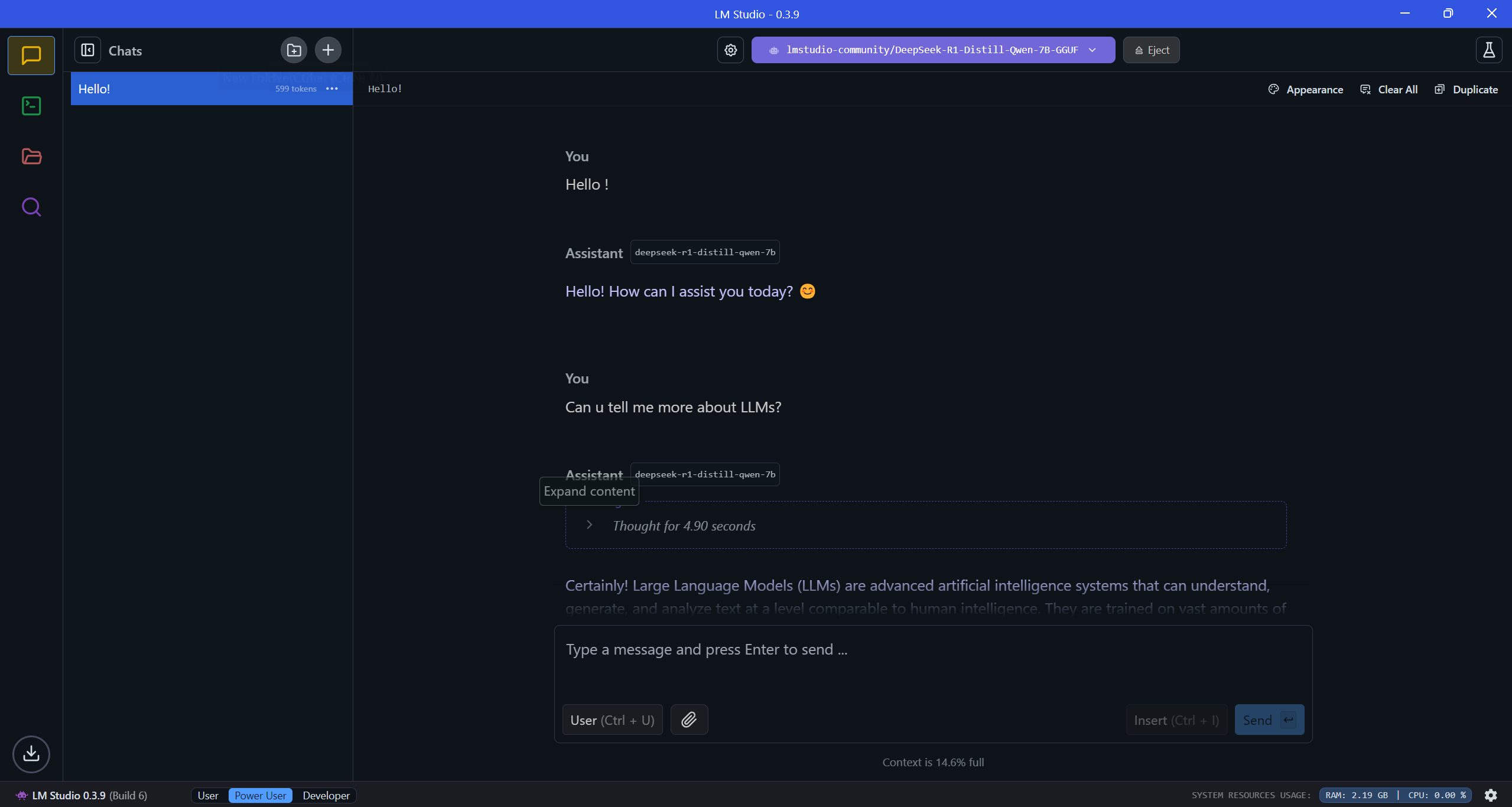
As you can see, it will answer just like any other online Generative AI chat.
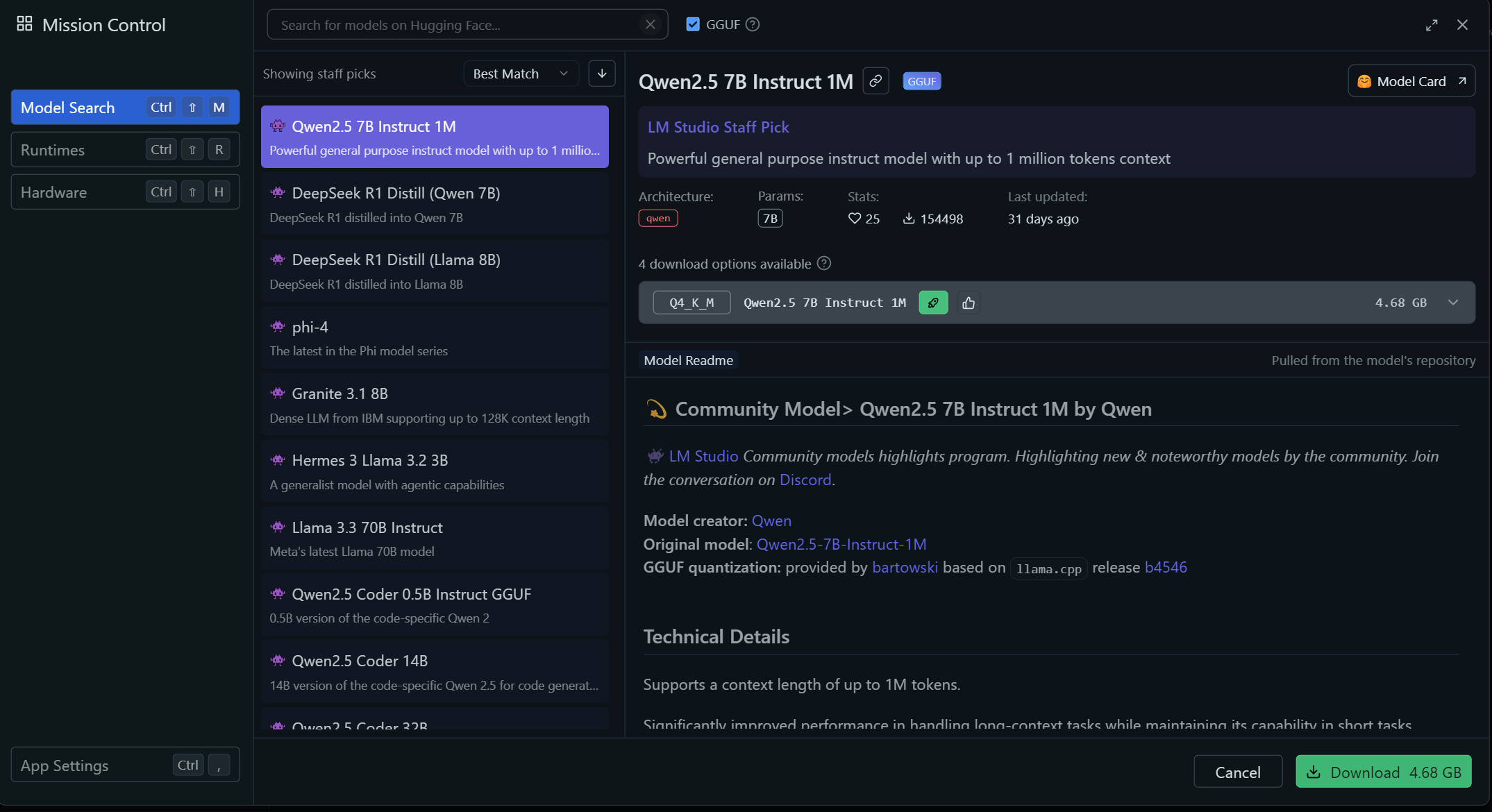
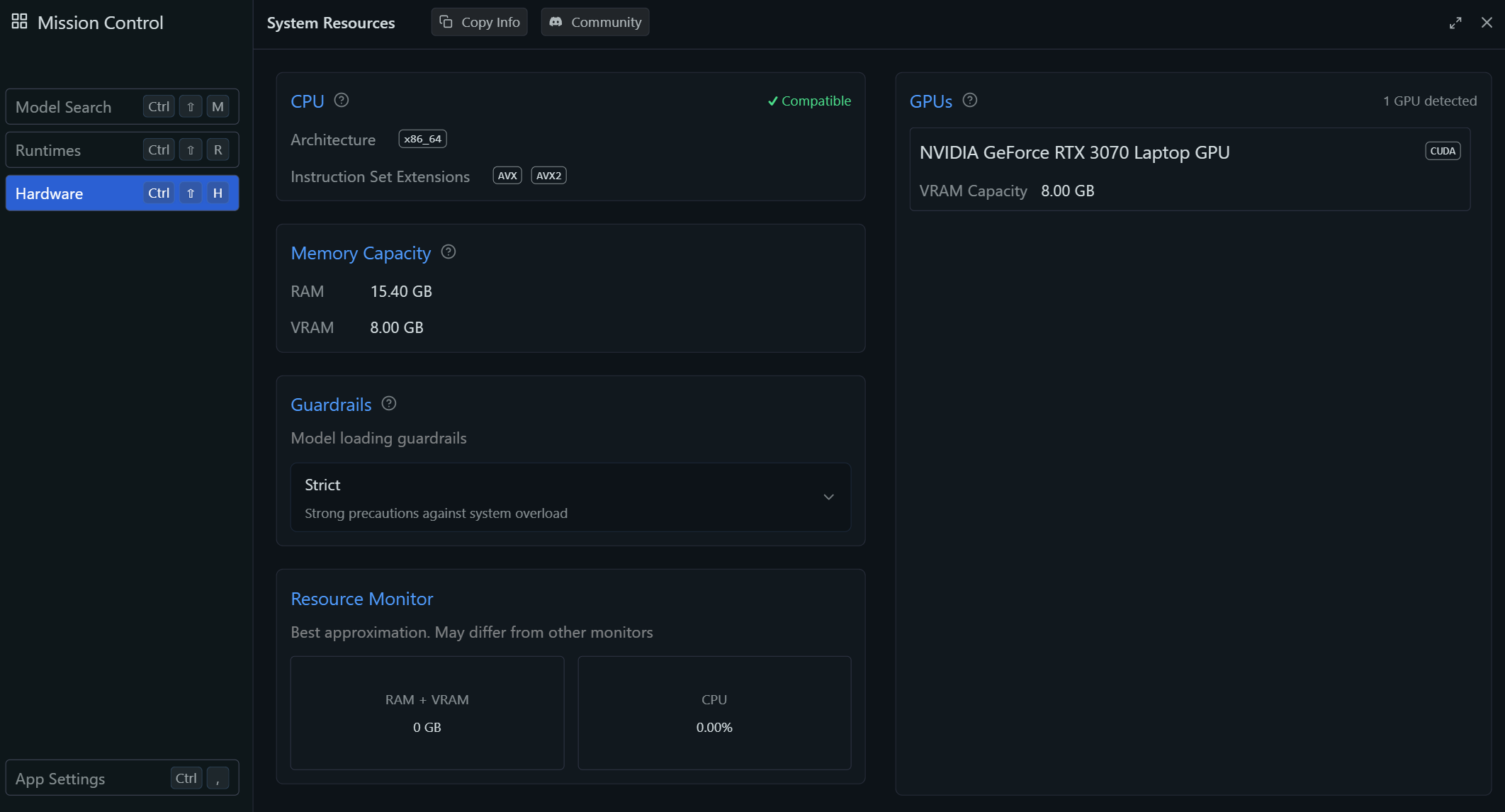
Under the “Discover” tab, you will be able to find many more available models. Most importantly, you will also be able to check your machine’s available resources, as well as set how much RAM is available to be used.
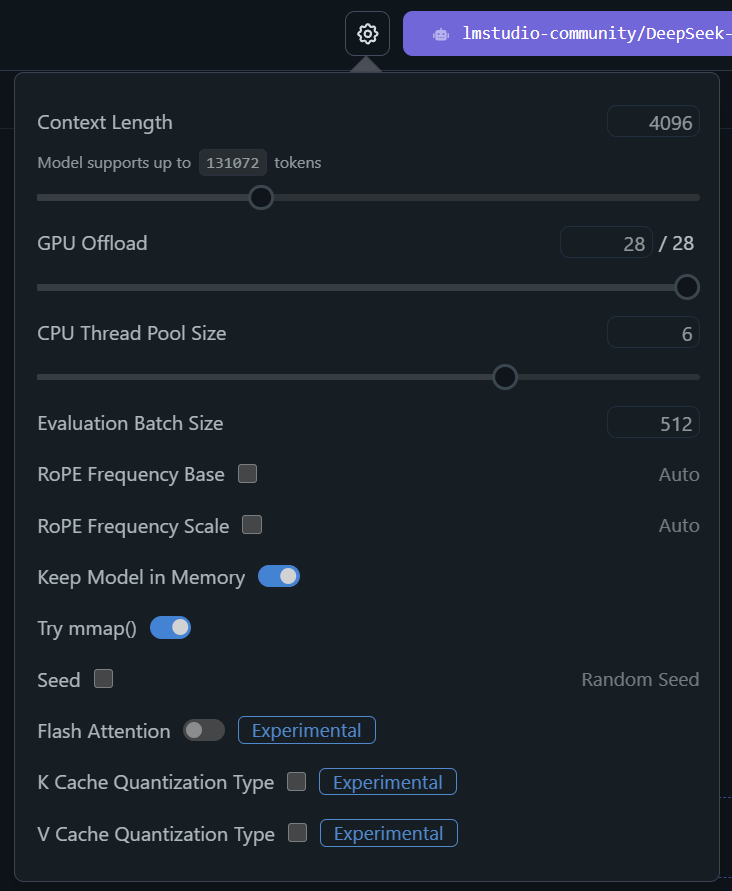
Furthermore, if you click on the Settings icon next to the model which is loaded, you can set many other parameters such as adjusting the Context Length or enabling the experimental Flash Attention feature.
Hosting LLMs on Your Local Network
To take this a step further, we would obviously like to utilize the model hosted on our AI rig on other machines. To do so, you simply have to start LM Studio’s Local LLM API Server. Navigate to the Develop, and in the top-left corner, click on the “Status” switch to start the server.
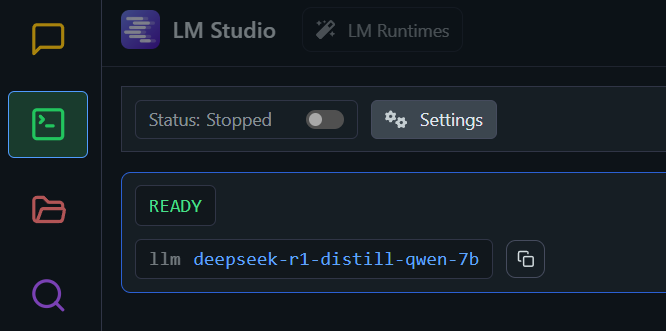

Once it is started, you can now access the model at the port displayed at the text “Reachable at:”. We can use curl to communicate with the model. For example:
curl http://127.0.0.1:1234/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\": \"local-model\", \"messages\": [{\"role\": \"user\", \"content\": \"Can you tell me more about LLMs?\"}]}"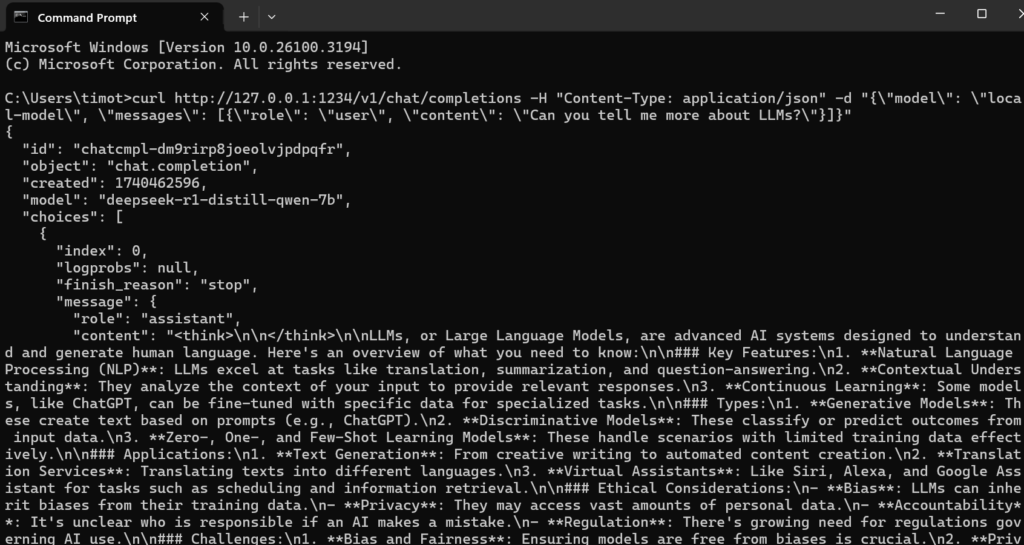
Of course, if you were to be querying it from another device, you would need to get the host IP Address by running ipconfig and replace the localhost IP Address with it.
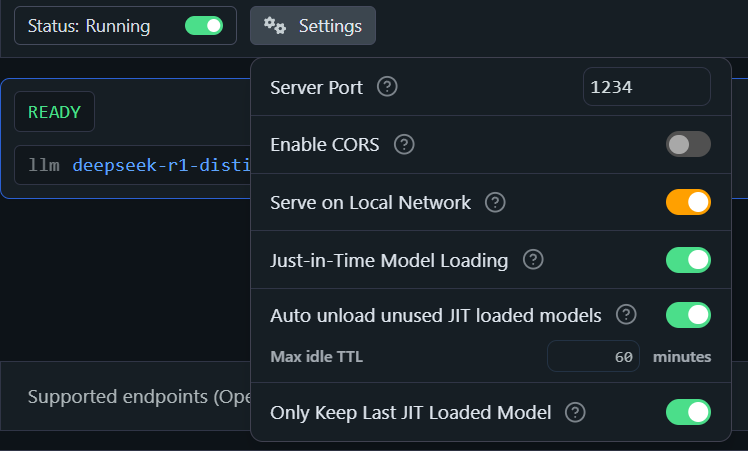
For that, make sure to also enable “Serve on Local Network” under “Settings”.
Simple Code Example
Naturally, you are also able to implement this in web or mobile apps, thus creating your own online Generative AI tool. One of the options is a Typescript SDK called lmstudio.js, which can be installed through npm. NOTE: This example will only work for a downgraded version of LM Studio (https://installers.lmstudio.ai/win32/x64/0.3.9-6/LM-Studio-0.3.9-6-x64.exe).
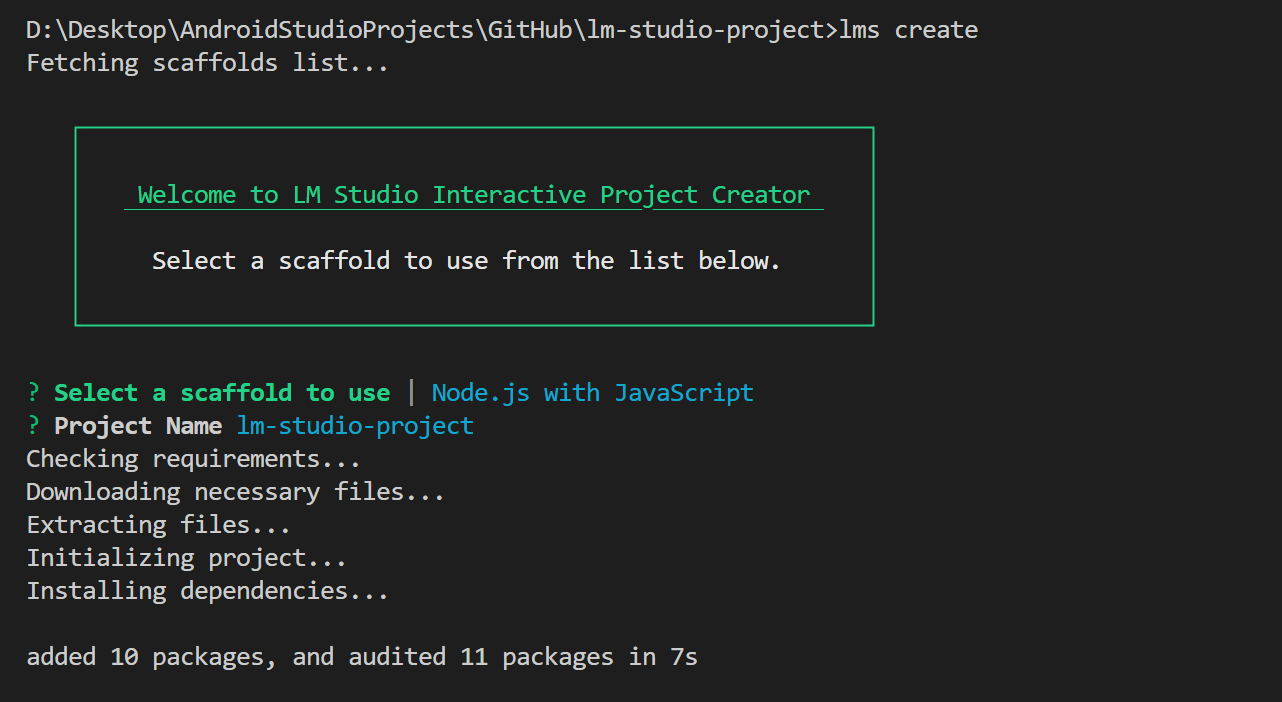
Create a new Folder. The one for this example will be called lm-studio-project. In the command line, run lms create. Select the first option, “Node.js with JavaScript” as the scaffold. Enter a suitable project name.
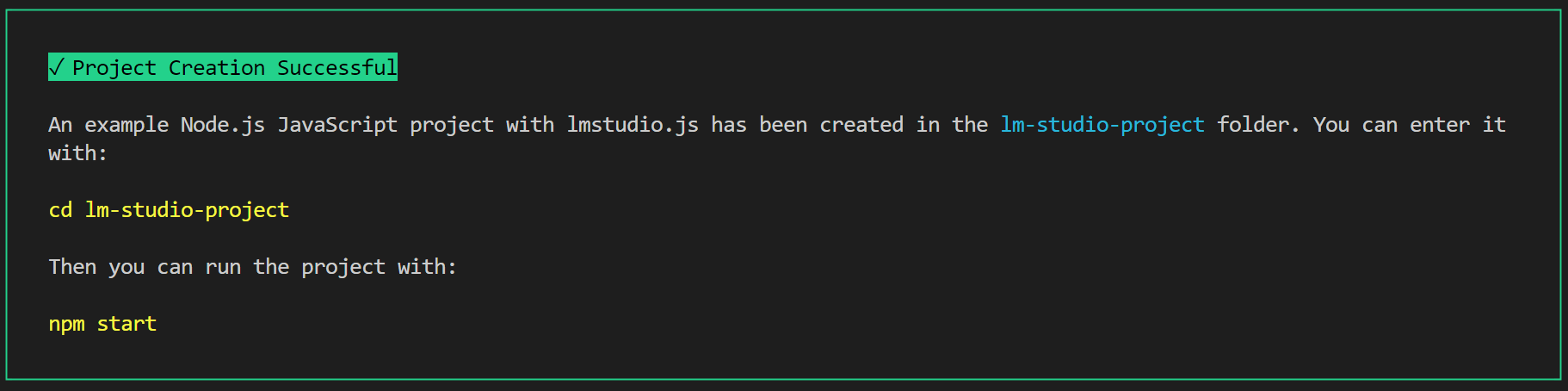
Once you have received this message, navigate to src/index.js. You will be able to see the boilerplate code provided by LM Studio. In the command line, make sure to navigate to the new folder by typing in cd YOUR-PROJECT-NAME.
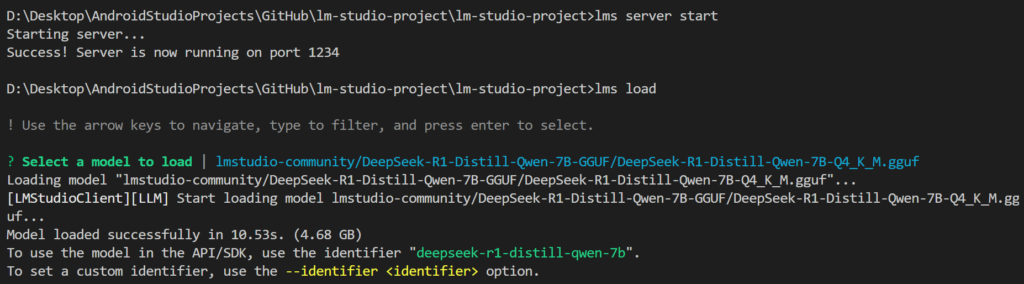
Next, type in lms server start, and then lms load. You will be prompted to select one of your downloaded models.
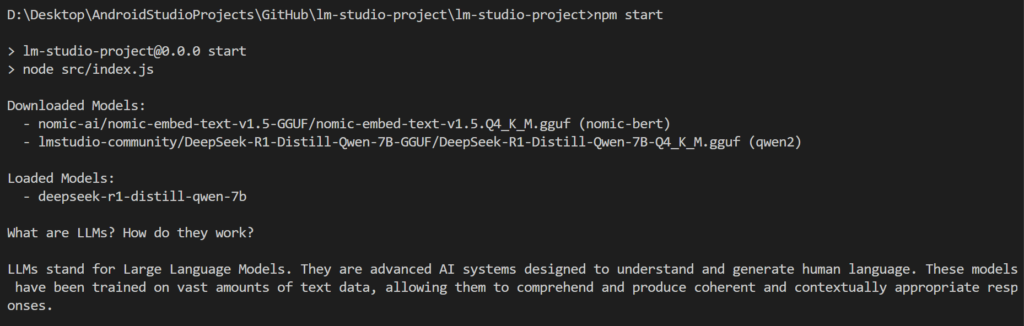
You are now ready to query your model by running npm start. There are 3 parameters which you can play around with in the predictWithAnyModel() function.
const prompt = "What are LLMs?"; // CHANGE PROMPT
const prediction = model.complete(prompt, {
maxPredictedTokens: 100, // CHANGE TO INCREASE RESPONSE LENGTH
temperature: 0.7, // CHANGE TO TWEAK CREATIVITY
});Future Considerations
Emerging Technologies
The landscape of local LLM deployment is rapidly evolving with the arrival of many promising technological advancements. These developments include specialized AI accelerators designed for consumer hardware such as Intel’s Neural Processing Unit (NPU). Furthermore, improved quantization techniques that maintain model quality while reducing resource requirements, such as SmoothQuant, allow users with lower-end hardware to run LLMs with close-to-original capacity.
Model Improvements
Model architectures are undergoing significant transformations to better accommodate local deployment scenarios, with a focus on reducing computational needs while maintaining performance. Key improvements include the development of more efficient attention mechanisms such as the Mistral 7B which utilizes Sliding Window Attention and Microsoft’s Phi-2 which employs Grouped Query Attention (GQA). There are also models specifically designed for efficiency like the TinyLlama (1.1B). These innovations demonstrate how smaller, more efficient architectures can achieve strong performance while requiring fewer computational resources.
Conclusion
In conclusion, it is clear that the technology behind Generative AI, which made headlines everywhere when it was popularized, is now easily accessible to consumers everywhere. Anyone who has access to some desktop-grade hardware will be able to run and host an LLM which can then be used within that network enabling AI capabilities that can rival any online tool. The field of Artificial Intelligence is enormous, and the best way to start learning about something is by starting at the practical level. Aspiring AI engineers should begin by trying to build and run their own Local LLM rigs, so that they can grasp fundamental technical concepts, understand limitations, as well as become a master of compatible hardware, rather than relying purely on theory.
